其他




NVIDIA DGX GH200超级服务器 系统架构
- 品牌:NVIDIA
- 型号:GH200
- 发货时间:3-5天
- 质保:365天
- 联系人:肖小姐
- 电话:15359021002(VX同号)
- QQ:577428784
- 邮箱:luckyxiao.909@gmail.com
-
产品详情
NVIDIA DGX GH200 系统架构
NVIDIA Grace Hopper 超级芯片和 NVLink Switch System 是 NVIDIA DGX GH200 架构的构建块。 NVIDIA Grace Hopper 超级芯片结合了 Grace 和 Hopper 架构,使用 NVIDIA NVLink-C2C以传递 CPU + GPU 相干存储器模型。 NVLink 交换系统由第四代 NVLink 技术提供动力,将 NVLink 连接扩展到超级芯片,以创建无缝、高带宽、多 GPU 系统。
NVIDIA DGX GH200 中的每个 NVIDIA Grace Hopper 超级芯片都有 480 GB LPDDR5 CPU 内存,与 DDR5 和 96 GB 快速 HBM3 相比,每 GB 的功率是其八分之一。 NVIDIA Grace CPU 和 Hopper GPU 与 NVLink-C2C 互连,以五分之一的功率提供比 PCIe Gen5 多 7 倍的带宽。
NVLink 交换系统形成了一个两级、无阻塞、fat-tree NVLink 结构,可在 DGX GH200 系统中完全连接 256 个 Grace Hopper 超级芯片。 DGX GH200 中的每个 GPU 都可以以 900GBps 访问所有 NVIDIA Grace CPU 的其他 GPU 和扩展 GPU 存储器。
托管 Grace Hopper 超级芯片的计算基板使用第一层 NVLink 结构的自定义线束连接到 NVLink 交换机系统。 LinkX 电缆扩展了 NVLink 结构第二层的连接。
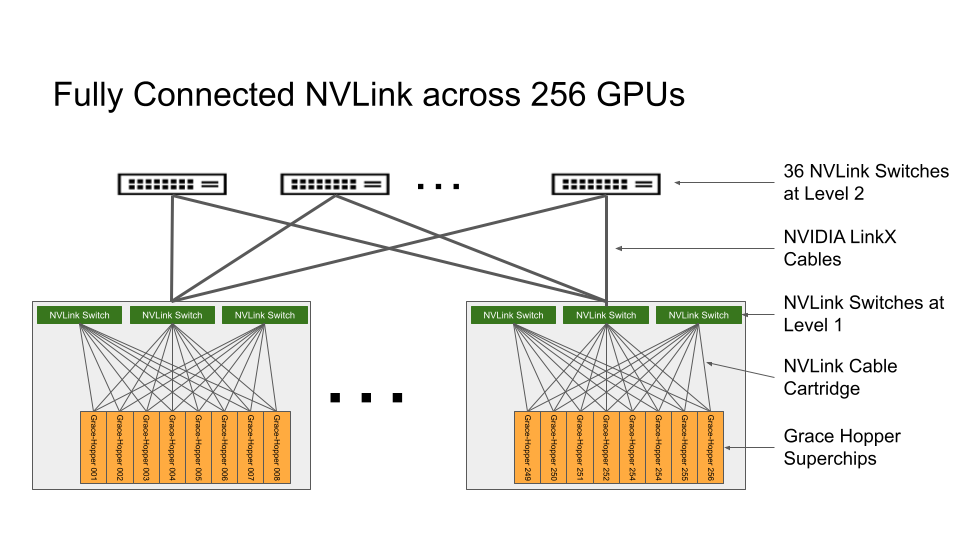
在 DGX GH200 系统中, GPU 线程可以使用 NVLink 页表从 NVLink 网络中的其他 Grace Hopper 超级芯片寻址对等 HBM3 和 LPDDR5X 内存。NVIDIA Magnum IO加速库优化了 GPU 通信以提高效率,并通过所有 256 个 GPU 来增强应用程序的可扩展性。
DGX GH200 中的每个 Grace Hopper 超级芯片都配有一个NVIDIA ConnectX-7网络适配器和一个NVIDIA BlueField-3 NICDGX GH200 在网络计算中具有 128 TBps 的双段带宽和 230 . 4 TFLOPS 的 NVIDIA SHARP ,以加速人工智能中常用的集体操作,并通过减少集体操作的通信开销使 NVLink 网络系统的有效带宽翻倍。
对于超过 256 GPU 的扩展, ConnectX-7 适配器可以将多个 DGX GH200 系统互连,以扩展到更大的解决方案中。 BlueField -3 DPU 的强大功能将任何企业计算环境转变为安全且加速的虚拟私有云,使组织能够在安全的多租户环境中运行应用程序工作负载。
目标使用案例和性能优势
GPU 内存的跨代显著提高了受 GPU ‘内存大小限制的 AI 和 HPC 应用程序的性能。许多主流 AI 和 HPC 工作负载可以完全驻留在单个NVIDIA DGX H100对于此类工作负载, DGX H100 是性能效率最高的培训解决方案。
其他工作负载,如具有数 TB 嵌入式表的深度学习推荐模型( DLRM )、数 TB 规模的图形神经网络训练模型或大数据分析工作负载,使用 DGX GH200 可实现 4 到 7 倍的加速。这表明 DGX GH200 是更先进的 AI 和 HPC 模型的更好解决方案,这些模型需要大量内存用于 GPU 共享内存编程。




栏目导航
新闻资讯
联系我们
电 话:15359021002
联系人:肖小姐
手 机:15359021002
邮 箱:luckyxiao.909@gmail.com
地 址:深圳市宝安区西乡街道臣田社区宝民二路东方雅苑2层B39